关于基于机器学习的多目标对象追踪算法的文献综述
问题描述
多目标对象追踪(Multi-Object Tracking, MOT)一直是计算机视觉(Computer Vision,CV)领域中非常重要的研究对象,其核心是通过分析输入的图像序列,构建出不同帧的物体间的对应关系。多目标对象追踪常被用于自动驾驶、人流量统计、水果分拣、嫌犯追踪等领域,在工业中存在着广泛的应用。
目前,研究者已经提出了许多的多目标对象追踪算法。按照工作流程分类,MOT 算法分为基于检测的追踪(Detection-Based Tracking, DBT)和无检测追踪(Detection-Free Tracking, DFT)两类[1]。DBT 依赖于对象检测,通常建立在一些已有的多目标对象检测及分类算法,如 YOLO[2] 等算法的基础上;而 DFT 则不需要对象检测的参与。有关 DBT 和 DFT 的特点可以参考表 1。
| DBT | DFT | |
|---|---|---|
| 初始化 | 自动;不完美 | 人工介入;完美 |
| 画面中对象数量 | 可变 | 固定不变 |
| 优点 | 无需人工介入,画面中物体数量可变 | 不需要识别器和分类器 |
| 缺点 | 性能受到识别器和分类器的限制 | 需要人工介入 |
| 常见应用场景 | 物体种类固定,画面中物体数量改变 | 物体种类不固定,但运动范围较小 |
而如果按照实现方法分类,多目标对象追踪算法可以被分成传统算法和基于机器学习的算法两类,其中传统算法通常工作在单摄像头场景下,基于机器学习的 MOT 算法在多摄像头场景下也工作良好,也更能适应工业上的多种应用需要[3]。因此,本文主要聚焦于近五年来提出的基于机器学习的 MOT 算法研究进展。
近期研究综述
近年来,随着机器学习理论和模型的不断发展,MOT 领域相关的研究热度也在持续上升。自 2017 年 DeepSORT[4] 被提出起,在短短的几年内涌现出一大批基于机器学习的高性能、高准确率的 MOT 算法,如 CenterTrack[5]、Tracktor++[6] 等。有些研究成果很好地解决了在某些特定领域内特定需求下的准确率问题,有些则提出了新的网络结构和模型架构,福泽所有在这一领域开展研究的研究人员。本文试图以时间顺序为主轴,按照这些研究所解决的问题的种类来分类不同的研究,并综述各研究的思路和主要成果。
虽然将机器学习引入 MOT 算法的研究很早以前就已经开展,但是真正在准确率上做出突破性提升的是 2017 年的 DeepSORT。DeepSORT 在原本的基于卡尔曼滤波(高斯滤波)预测和匈牙利匹配计算最优解的 SORT[7] 算法的基础上引入了深度学习的概念,在一个大规模的行人重识别数据集上训练,增加了对图像部分缺失和短时间遮挡的鲁棒性,同时保持了算法的高效性[4]。并且 DeepSORT 是一个在线(Online)算法,其在识别物体关联和轨迹时只需要参考过往的信息,无需参考未来的图像,因此它能够工作在实时输入的视频流上,使用场景更广。
不过,由于 DeepSORT 仍然工作在 SORT 基础上,因此 SORT 存在的缺陷仍然会在 DeepSORT 中存在。例如,SORT 采用卡尔曼滤波预测物体在下一帧中的位置。卡尔曼滤波为贝叶斯滤波在置信度用多元正态分布的特殊情况下推导得出,可得其函数表示如下: \[ p(x)=\det(2\pi S)^{-\frac{1}{2}}\exp\left( -\frac{1}{2}(x-\mu)^{T}S^{-1}(x-\mu)\right)\\ \] 其中,\(\mu\) 为样本均值,\(S\) 为样本方差。然而实际上,由相机录制的视频往往存在不满足正态分布的位移扰动如手持相机导致的不规律抖动,不难想到此时卡尔曼滤波模型产生的结果的准确度会降低。这也是 DeepSORT 算法的主要缺点。
在随后的一段时间内,虽然又有一些基于机器学习的 MOT 算法被提出,但它们对准确率的提升微乎其微,甚至在两年中仅仅使得最佳准确率(State-of-the-Art,SOTA)提升了 2%[1]。这时,Bergmann 团队在 ICCV2019 上发布了 Tracktor 算法的论文[6]。这篇论文不仅部分否定了过去两年中全世界研究人员普遍采用的检测器和追踪器配合的思路、简化了此前的网络模型,还对 SOTA 的提升做出了贡献。具体来讲,Bergmann 团队尝试了仅仅使用检测器和物体检测算法,通过引入回归层来调优物体检测的外接矩形(Bounding Box)位置的做法,实现了性能优秀且准确率高的 MOT 算法。这种实现方式的优势主要有两点:首先,无需额外训练追踪器,不仅节约了算力,也降低了性能和功耗要求;再者,检测器全部为在线算法,回归层也只需要参考此前的输入和输出,因此 Tracktor 算法同样是在线算法。不过,Tracktor 算法也同样存在一定的缺点。例如,Tracktor 无法解决由于物体相互遮挡导致身份交换(Identify Switch,IDSW)的问题。为了解决这一问题,在同一篇论文中作者还提出了 Tracktor++ 算法,通过引入短期(Short-Term)身份重识别(Re-Identification, ReID),基于 Siamese Network 提取出物体的表面特征来帮助匹配[6]。然而,加入 ReID 导致了计算耗时的增加和性能的下降,为此作者还额外提出了通过等速假设和增强型相关系数最大化这两种运动模型(Motion Model)来改善预测的外接矩形在下一帧中的位置以减少 ReID 匹配耗时。
这一阶段同样有一些别的改进 DeepSORT 的研究,例如有一些 MOT 爱好者在私下尝试将 DeepSORT 中的 SORT 部分替换为其它的目标检测算法如 YOLOv4 甚至 YOLOv5,同样也取得了接近 SOTA 的效果,并且摆脱了 SORT 算法的固有缺陷。在正式的期刊中同样出现了类似的研究,例如有团队提出通过遮挡组管理(Occlusion Group Management)来改进 DeepSORT 算法的匹配部分[8]。然而 2020 年提出的 CenterTrack 算法[5] 指出了他们所采用的检测器和追踪器同时训练(Joint Learning the Detector and Embedding Model,JDE)方法中存在的固有缺陷,2021 年提出的 FairMOT 算法[9] 同样也注意到了这些缺陷。二者均在传统的 JDE 基础上做出了有针对性的改进,通过将 Anchor-Based 检测替换为 Anchor-Free 检测,缓解了这些问题,在多个数据集上取得了 SOTA 的成绩。在 FairMOT 的论文中,作者提出,目前 JDE 训练的检测方式为同时提取检测框和检测框内物体的 ReID 信息,然而由于同一个物体可能出现在多个检测框中,会导致较高的网络模糊性。同时,物体的实际中心可能并不是其外接矩形的几何中心,这就可能导通过几何中心计算出的位移距离和实际位移距离存在偏差。CenterTrack 算法采用了基于其灵感来源 CenterNet 的基于物体实际中心点的检测[10],采用这种方式能够更加准确地提取到物体的特征用于 ReID 层,可以更好地避免身份互换的问题。FairMOT 算法同样采用了基于物体实际中心点的特征检测,并且还引入了类似编码器和解码器模型(Encoder-Decoder Model)的网络,通过逐层降采样、分层提取特征信息的方式产生经过融合的多层信息,恰好满足了 ReID 算法需要多层融合信息的需求。提取出的高分辨率特征信息将根据其维度分别送入检测器和 ReID 层,最终取得了很好的效果。
除了改进基于 ReID 的匹配算法外,也有一些研究聚焦于如何更好地计算不同实例的相似度以提升准确率。Pang 团队在 2021 年提出了 QDTrack 算法[11] 便是如此。Pang 团队认为,此前工作仅仅利用像素级先验知识进行追踪,这种方法大多只适合一些简单的场景,当目标较多、存在大量遮挡或拥挤现象时,单纯基于位置信息的匹配很容易产生错误的结果。因此,QDTrack 通过拟密集(Quasi-Dense)匹配,支持在一张图片中创建上百个兴趣区域,通过对比损失以学习网络参数,尽可能多地利用图片中的已有信息。下图为展示 QDTrack 创建上百个兴趣区域的示意图。
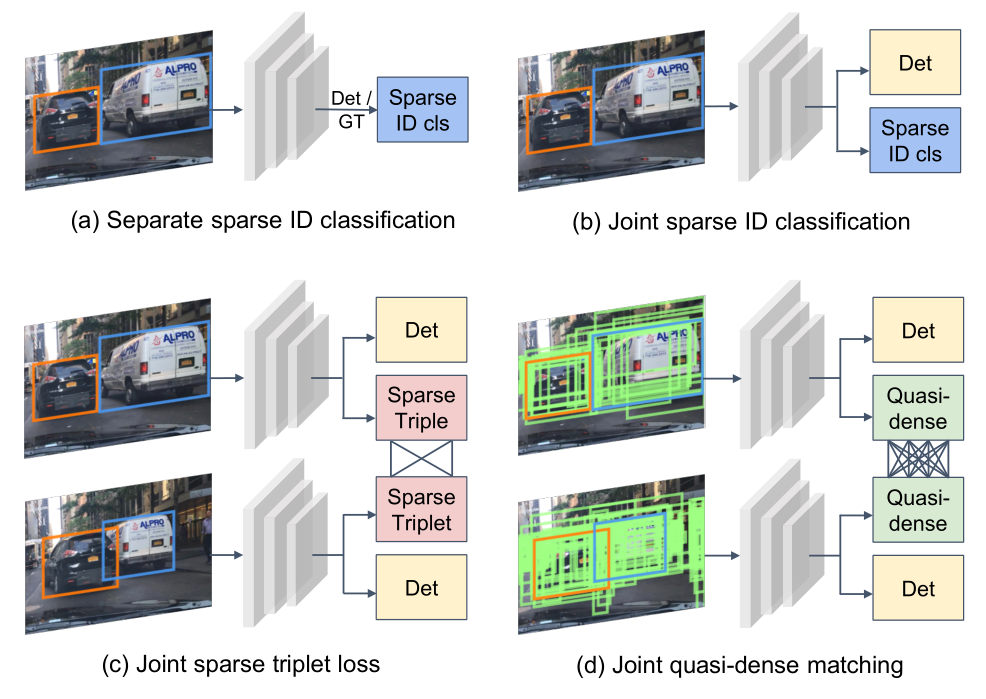
同时,由于目标较多的场合下一定会频繁出现新目标进入画面和已有目标在画面边缘消失的情况,因此作者将背景单独作为一类参与训练和匹配,从而能够通过双向 Softmax 函数增强一致性。由于学习到的实例相似度特征太好,在最终的关联步骤即使是仅仅采用最简单的最近邻搜索也能得到非常好的匹配准确率。QDTrack 在采用了 Softmax 函数后的目标函数如下所示[11]: \[ \mathcal{L}_e=\log \left[1+\sum_{\mathbf{k}^{+}} \sum_{\mathbf{k}^{-}} \exp \left(\mathbf{v} \cdot \mathbf{k}^{-}-\mathbf{v} \cdot \mathbf{k}^{+}\right)\right] \] 其中,\(\mathbf v, \mathbf{k}^{+}, \mathbf{k}^{-}\) 分别为训练样本、正目标样本和负目标样本的特征嵌入(Embedding)。这里的 Embedding 指的是是一种把原始输入数据分布地表示成一系列特征的线性组合的表示方法。
随后的研究表明,Quasi-Dense 特征匹配方案的泛化性很强。Hu et al. 在 2022 年将 Quasi-Dense 泛化到三维空间中的多目标对象匹配问题上,提出了 QD-3DT 算法[12]。该算法能够基于单目摄像头的二维的图像序列输入,给出估计的物体在三维空间中的外接矩形,并且在相邻帧中以高准确率和良好的性能匹配识别到的物体。论文作者在自动驾驶的常见场景下测试了该算法,取得了非常优秀的结果。需要注意的是,自动驾驶的应用场景比较特殊,涉及到人类的生命安全,故通常要求算法的鲁棒性极高。QD-3DT 在测试中很好地适应了雨天和夜晚等行驶条件,证明了拟密集匹配算法的优越性[12]。
未来展望
目前看来,2021 年前后提出的一些算法和模型(如 QDTrack)已经能够满足绝大多数场景下的使用需求,二维场景下的多目标匹配问题可以认为已经得到了较好的解决。因此,未来的发展或许主要会聚焦在两个方向上:第一个方向是使得学术界的模型能够尽快在工业届投入使用,在实践中检验模型存在的不足,并尝试逐步替换掉目前广泛使用的 DeepSORT 模型;第二个方向是尝试将上述算法泛化、迁移至 3D 领域,解决三维空间中的多对象匹配问题,从而更好地服务于自动驾驶和工业控制等领域。不过,在解决三维空间中多对象匹配问题时,可能需要模型有能力接受来自不同位置的多个摄像头的输入以增强匹配的准确度,此方向的研究暂时还比较空白。考虑到工业届对这类算法存在较大的需求,可以预计在未来一定会有一些优秀的相关成果出现。
参考文献
[1] Luo, W., Xing, J., Milan, A., Zhang, X., Liu, W., & Kim, T.-K. (2021). Multiple object tracking: A literature review. Artificial Intelligence, 293, 103448. https://doi.org/10.1016/j.artint.2020.103448
[2] Bochkovskiy, A., Wang, C.-Y., & Liao, H.-Y. M. (2020). YOLOv4: Optimal Speed and Accuracy of Object Detection. doi:10.48550/ARXIV.2004.10934
[3] Kalake, L., Wan, W., & Hou, L. (2021). Analysis based on recent deep learning approaches applied in real-time multi-object tracking: A Review. IEEE Access, 9, 32650–32671. https://doi.org/10.1109/access.2021.3060821
[4] Wojke, N., Bewley, A., & Paulus, D. (2017). Simple online and realtime tracking with a Deep Association metric. 2017 IEEE International Conference on Image Processing (ICIP). https://doi.org/10.1109/icip.2017.8296962
[5] Zhou, X., Koltun, V., & Krähenbühl, P. (2020). Tracking objects as points. Computer Vision – ECCV 2020, 474–490. https://doi.org/10.1007/978-3-030-58548-8_28
[6] Bergmann, P., Meinhardt, T., & Leal-Taixe, L. (2019). Tracking without bells and whistles. 2019 IEEE/CVF International Conference on Computer Vision (ICCV). https://doi.org/10.1109/iccv.2019.00103
[7] Bewley, A., Ge, Z., Ott, L., Ramos, F., & Upcroft, B. (2016). Simple online and realtime tracking. 2016 IEEE International Conference on Image Processing (ICIP). https://doi.org/10.1109/icip.2016.7533003
[8] Song, Y.-M., Yoon, K., Yoon, Y.-C., Yow, K. C., & Jeon, M. (2019). Online multi-object tracking with GMPHD Filter and Occlusion Group management. IEEE Access, 7, 165103–165121. https://doi.org/10.1109/access.2019.2953276
[9] Zhang, Y., Wang, C., Wang, X., Zeng, W., & Liu, W. (2021). FairMOT: On the fairness of detection and re-identification in multiple object tracking. International Journal of Computer Vision, 129(11), 3069–3087. https://doi.org/10.1007/s11263-021-01513-4
[10] Duan, K., Bai, S., Xie, L., Qi, H., Huang, Q., & Tian, Q. (2019). CenterNet: Keypoint Triplets for object detection. 2019 IEEE/CVF International Conference on Computer Vision (ICCV). https://doi.org/10.1109/iccv.2019.00667
[11] Pang, J., Qiu, L., Li, X., Chen, H., Li, Q., Darrell, T., & Yu, F. (2021). Quasi-dense similarity learning for multiple object tracking. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). https://doi.org/10.1109/cvpr46437.2021.00023
[12] Hu, H.-N., Yang, Y.-H., Fischer, T., Darrell, T., Yu, F., & Sun, M. (2022). Monocular quasi-dense 3D object tracking. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1–1. https://doi.org/10.1109/tpami.2022.3168781